

Anthropic shipped Claude Opus 4.8 last week. It's a modest but tangible upgrade on 4.7, with sharper judgement, better tool use, and a noticeable jump in honesty. The pricing hasn't changed, the API name has, and there are a few new features alongside it worth knowing about.
Here's what's actually new, what it means in practice, and whether you need to do anything about it.
In This Guide
- What changed between Opus 4.7 and 4.8
- The headline benchmarks (and how to read them)
- The honesty upgrade and why it matters for business use
- New features: effort control, dynamic workflows, mid-task system updates
- What this means for your team and whether you need to do anything
What's New in Opus 4.8
Anthropic isn't pitching Opus 4.8 as a generational leap. It's an iterative update, and they're upfront about that. The headline is "more reliable, sharper judgement, better tool use" rather than "a whole new class of capability."
But the practical changes are useful enough to be worth a five-minute read, especially if your team is already using Claude for real work.
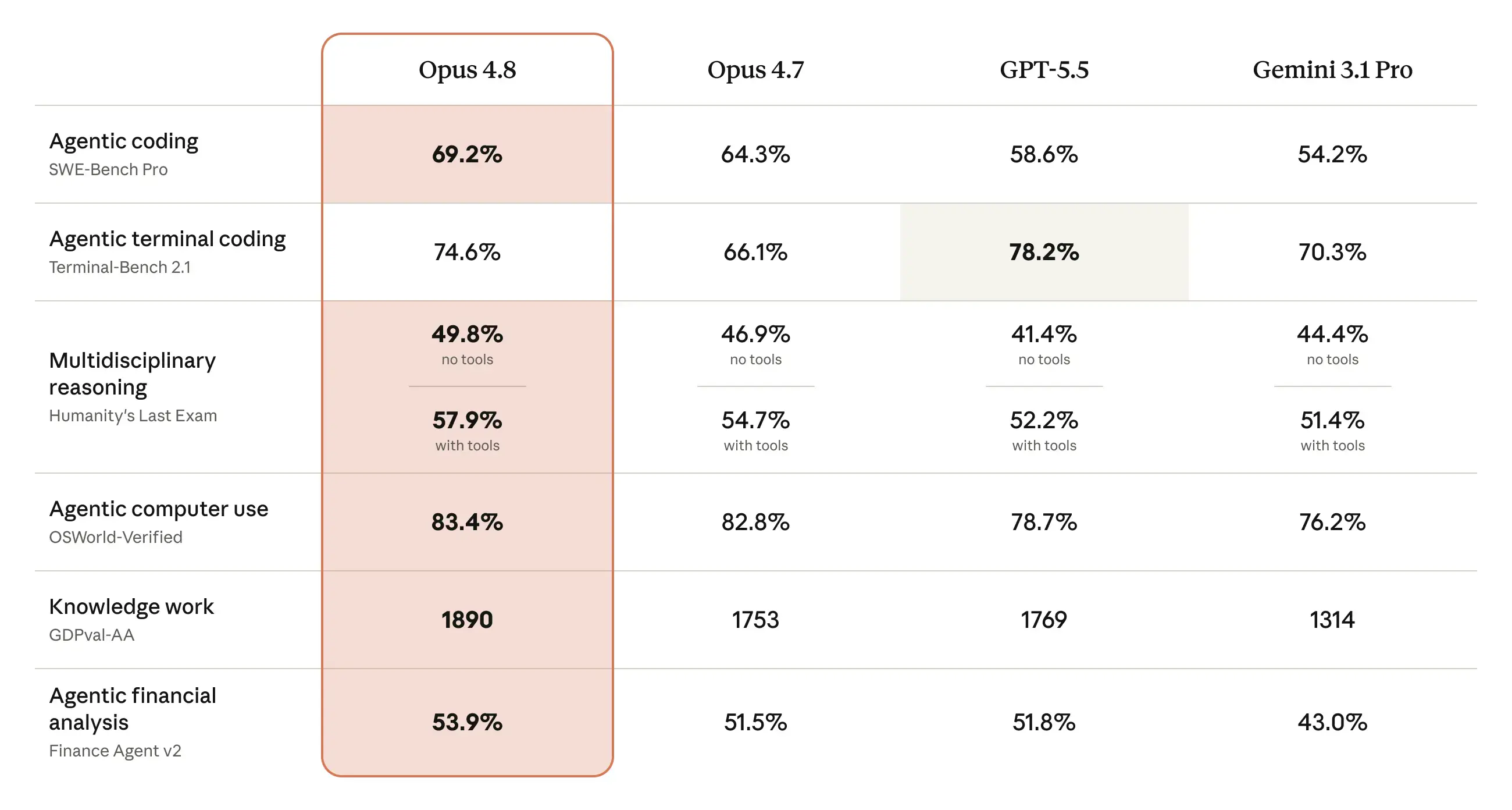
Source: Anthropic Opus 4.8 launch announcement. Opus 4.8 leads in every benchmark except agentic terminal coding (Terminal-Bench 2.1), where GPT-5.5 still edges ahead.
The Big Three Changes
- Better judgement on agentic work. The model is more reliable when running long, multi-step tasks. It asks the right questions, catches its own mistakes, and pushes back when a plan doesn't make sense.
- A real jump in honesty. Anthropic say Opus 4.8 is around four times less likely than 4.7 to let flaws in its own code pass unremarked. It flags uncertainty instead of bluffing through it.
- Tool use is more efficient. Same outcomes, fewer steps, fewer tokens. Useful if you're paying per call or running agents at scale.
The Benchmarks That Matter
Anthropic published a wide set of benchmark comparisons. A few stand out as actually relevant to business use:
Online-Mind2Web: 84%
This measures how well a model can use a browser to complete real web tasks. Opus 4.8 hits 84%, a meaningful jump over 4.7 and ahead of GPT-5.5. If you're building (or considering) browser-based AI agents that book travel, fill forms, or pull data from web apps, this is the benchmark to watch.
SWE-Bench: Software Engineering
For coding agents and Claude Code specifically, Opus 4.8 outperforms 4.7 across every effort level. The model uses fewer steps for the same outcome and is better at carrying tasks end-to-end instead of giving up halfway through.
Legal Agent Benchmark
Opus 4.8 set the highest recorded score on this benchmark and is the first model to break 10% on the all-pass standard. For anyone using AI in regulated professional services, this is the kind of accuracy lift that translates directly into how much real work can be delegated with confidence.
Super-Agent Benchmark
The only model so far to complete every test case end-to-end. This is the one that matters for translation, deep research, slide-building, and analysis workloads.
The Honesty Upgrade
This one deserves its own section because it's the change most likely to affect day-to-day use.
One of the persistent problems with large language models is confident bluffing. The model finishes a task and says "done" when actually it skipped something, made an assumption, or quietly failed. You only find out later when something breaks downstream.
Opus 4.8 is materially better at flagging uncertainty. Early testers report it's more likely to say "I'm not sure about this" or "this assumption could be wrong" instead of pressing on regardless. Anthropic's own evaluations show it's around four times less likely than 4.7 to let flaws in its code pass unremarked.
For business use, this is the kind of upgrade that quietly reduces risk. Fewer false-positive completions, more "this might need a human review" moments. It makes the model more useful for high-stakes work like contract review, financial analysis, or regulated workflows where being wrong is more expensive than being slow.
Aztech take
The honesty improvement is the single most important practical change in 4.8. If you've been hesitant to put AI into workflows where "looks right" isn't good enough, this is the upgrade that makes the conversation easier.
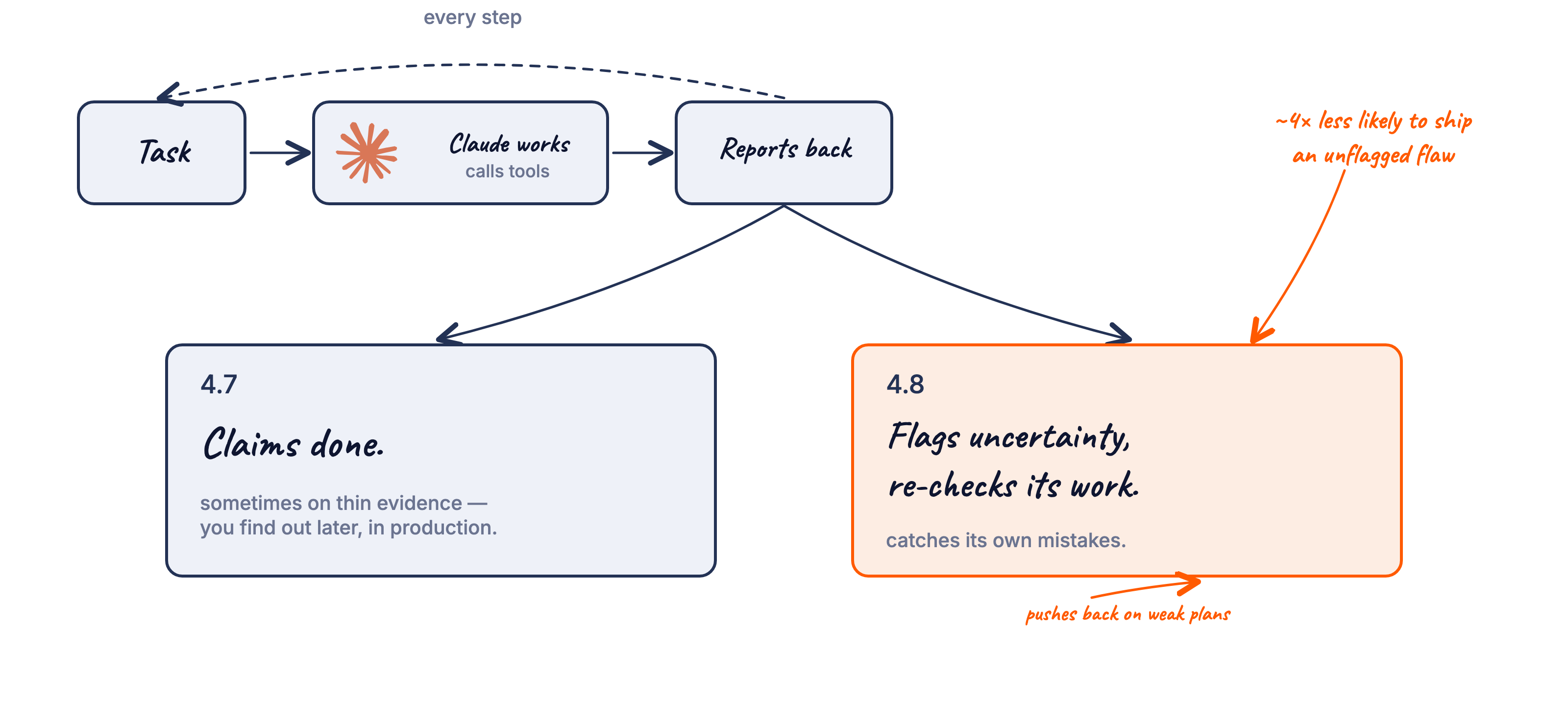
Opus 4.8 is around four times less likely than 4.7 to ship an unflagged flaw. It re-checks every step instead of trusting its first answer.
What Else Launched Alongside 4.8
Three new features shipped at the same time, and they're worth knowing about even if you're not building on the API directly.
Effort Control
You can now choose how much effort Claude puts into a response. It sits alongside the model selector in claude.ai and Cowork. Higher effort means the model thinks longer and produces better results. Lower effort means faster responses and slower burn of your rate limits.
Opus 4.8 defaults to "high" effort, which Anthropic say is the best balance of quality and experience. You can dial it up to "extra" or "max" for harder tasks, or down for quick chat. Worth a look if your team uses Claude heavily and runs into rate limits.
Dynamic Workflows in Claude Code
If you're already using Claude Code, this is the biggest practical change in 4.8. Dynamic workflows let Claude take on tasks that previously needed to be broken into dozens of separate prompts - and just get on with the whole thing in one session.
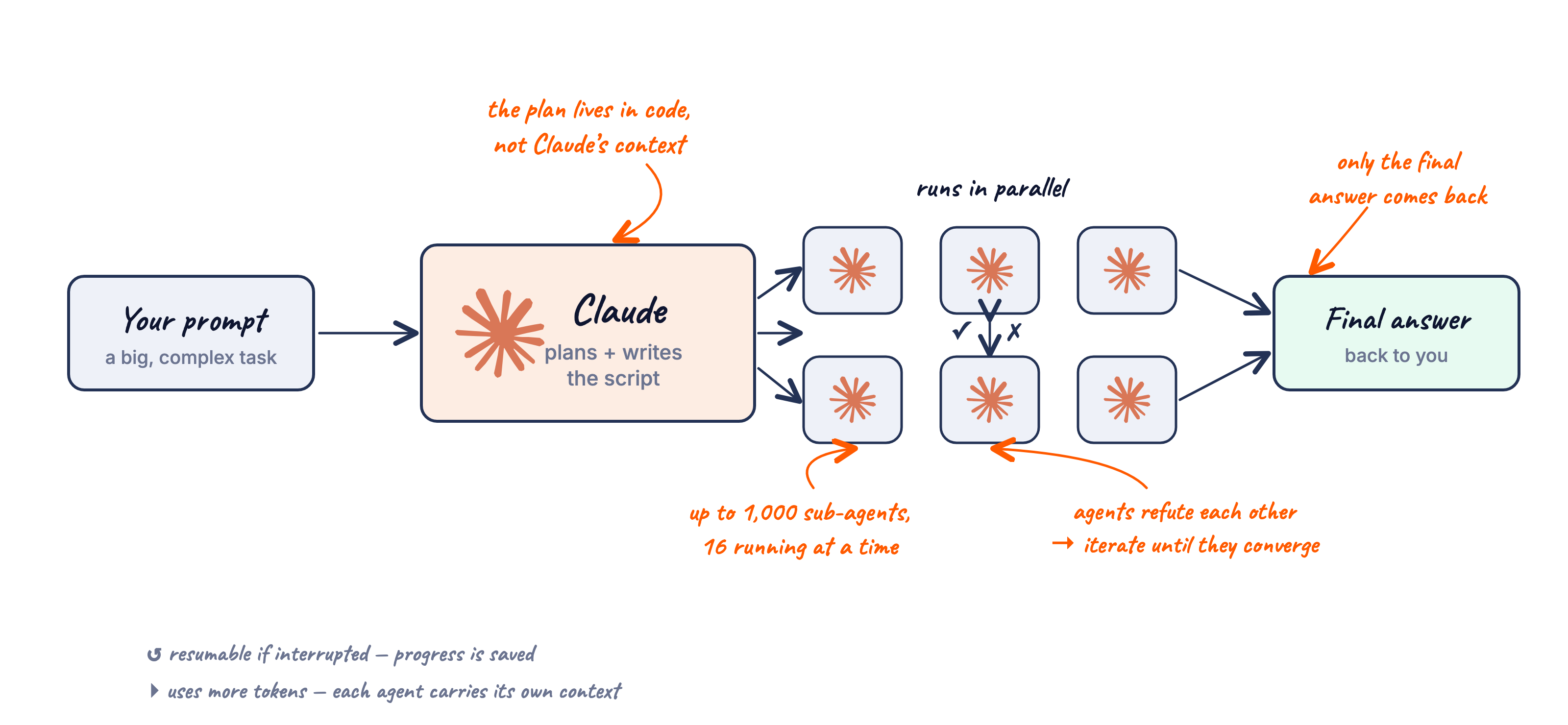
Dynamic workflows let Claude plan, write a script, spawn hundreds of sub-agents in parallel, and only return when the work converges. The plan lives in code, not Claude's context window - which is what makes the whole thing scalable.
How it works in practice
You give Claude Code a big task. It plans the work out as a script and then spawns up to 1,000 sub-agents (running 16 at a time) to execute it in parallel. Each sub-agent carries its own context, runs to completion, and reports its result back. Agents that disagree push back on each other and iterate until they converge. Only the final, verified answer comes back to you.
Crucially, the plan lives in code rather than Claude's context window. That's the structural change that makes the whole thing scalable - the orchestrator doesn't drown in its own state. If a session is interrupted, the progress is saved and resumable from where it stopped.
How to trigger it
You don't need a special command. In Claude Code, just describe a task that is genuinely too large for a single prompt - cross-cutting changes across hundreds of files, repeated transformations on large datasets, multi-step analysis across many sources - and Claude will recognise the shape of the problem and propose a dynamic workflow plan. You approve the plan, and it executes.
Anthropic recommend using the "extra" effort setting ("xhigh" in Claude Code) for dynamic workflow tasks. Rate limits in Claude Code have been raised to accommodate the higher token usage, and dynamic workflows are available on Enterprise, Team, and Max plans.
A word of caution on cost
Dynamic workflows are powerful, but they are not the kind of feature you want to fire off for every task. Running hundreds of sub-agents in parallel at the highest effort setting burns through tokens fast - one large session can easily cost more than a full day of normal Claude Code usage. Think before invoking one. Ask yourself whether the task genuinely needs scale (hundreds of similar operations) or whether a single Claude Code session would do the job for a fraction of the cost. Used in the right place, dynamic workflows are excellent value. Used carelessly, they are an expensive way to do something you could have done cheaper.
Where it actually pays off
The big use cases we'd expect to see for clients:
- Codebase-scale migrations. Anthropic's own example is upgrading a framework or library version across hundreds of thousands of lines of code, with the test suite as the bar for success. Previously, a multi-week refactor. With dynamic workflows, "kickoff to merge" in one session.
- Large-scale code audits. Security or compliance reviews that need to check every file against a defined rule set. Each sub-agent takes a slice of the codebase, applies the same rules, and reports back consistent findings.
- Bulk content or document processing. Reviewing every contract for a specific clause, every report for a specific data point, every policy document for compliance with a new regulation. The kind of work that would normally need a team of analysts.
- Test coverage and quality work. Going through an entire codebase and writing tests for every function that doesn't have one. Or fixing every flagged warning across a project. Mechanical work that benefits from parallelism.
- Multi-source research at depth. Pulling and synthesising information from many sources where each one needs proper reading, not just a quick scan.
The pattern that fits dynamic workflows is "large but uniform" - many things that need the same kind of treatment. If the task is "do one careful thing", regular Claude Code is still the right tool. If it's "do this same thing across 500 places", dynamic workflows is where it earns its keep.
Mid-task System Updates
Smaller and more technical, but useful if you're building on the API. The Messages API now accepts system entries inside the messages array, meaning developers can update Claude's instructions mid-task without breaking the prompt cache. This is the kind of plumbing improvement that makes long-running agent workloads more reliable.
What This Means For Your Team
If you're using Claude in claude.ai or Cowork
You don't need to do anything. Opus 4.8 is already the default. You'll just notice the model is a bit better at long conversations, more honest when it's not sure, and the effort control gives you a useful new dial to play with. Same price.
If you're building on the API
Update your model name to claude-opus-4-8. Pricing is unchanged ($5/M input, $25/M output for regular usage, $10/$50 for fast mode). Worth re-running your evals against 4.8 to confirm the upgrade is actually a net positive for your specific use case. Most teams will see a quiet improvement, but if your prompts are heavily tuned to 4.7 behaviour, there may be edge cases worth checking.
If you're running coding agents
The tool-calling efficiency gains are real. Same outcomes, fewer steps, fewer tokens. Combined with dynamic workflows (on the right plan), there's a meaningful jump in what you can hand off to a coding agent unattended.
If you're evaluating AI vendors
This release narrows the practical gap between top-tier models even further. Anthropic, OpenAI, and Google are all shipping iterative improvements every few weeks now. Picking a vendor based on "which model is best today" is a losing strategy. Pick based on which platform fits your security, compliance, and integration requirements, and assume the model itself will be competitive within weeks regardless of who you choose.
What's Coming Next
Anthropic also signalled what's next. Two things worth flagging:
- Cheaper models with Opus-level capability. They're working on bringing the same kind of capability down to a lower price tier. No timeline given.
- Claude Mythos for everyone (eventually). Mythos is Anthropic's frontier model that's currently only available to Project Glasswing partners for cybersecurity work. It needs more safeguards before general release, but Anthropic say they're making "swift progress" and expect to make it available to all customers in the coming weeks.
The Mythos rollout is the bigger story to watch. We covered the full implications when it was first announced in our breakdown of the launch. When it's generally available, the conversation shifts again.
The Aztech View
4.8 isn't a release that demands action, but it's worth knowing about. The honesty upgrade is the change most likely to affect your day-to-day use, and it's the one that makes Claude more usable in workflows where "confident but wrong" used to be a real risk.
For anyone building on Claude, the tool-call efficiency and dynamic workflows are the parts that translate to real cost savings and bigger automated tasks. For everyone else, you'll just feel the model is a bit sharper than it was last week.
The bigger picture remains the same as it's been all year: the gap between iterative AI improvements and a real generational shift is now measured in weeks, not years. The teams that stay close to these releases and run small experiments often are the ones who'll get the compounding advantage. The teams that wait for the "stable" version will be a year behind, every year.
Want help thinking through Claude or AI strategy for your team?
Book a free 30-minute AI discovery call. We'll talk through where AI fits in your operation, what's worth piloting now, and what to ignore. No sales pitch.
Book a Discovery CallFrequently Asked Questions
Do I need to update anything to use Opus 4.8?
If you use claude.ai or Claude Cowork, no. It's already the default. If you're using the API directly, update your model identifier to claude-opus-4-8.
Is Opus 4.8 more expensive than 4.7?
No. Pricing is unchanged: $5 per million input tokens, $25 per million output tokens for regular usage. Fast mode is $10/$50 and is now three times cheaper than fast mode on earlier Opus models.
What's the biggest practical difference between 4.7 and 4.8?
Honesty. Opus 4.8 is around four times less likely than 4.7 to let flaws in its own work pass unremarked. It flags uncertainty rather than bluffing. For business workflows where being wrong is more expensive than being slow, this matters.
What is effort control?
A new control in claude.ai and Cowork that lets you choose how much effort the model puts into a response. Higher effort means deeper thinking and better answers. Lower effort means faster responses and less rate limit consumption. Available on all plans.
What are dynamic workflows in Claude Code?
A new feature in research preview that lets Claude Code plan large tasks, run hundreds of parallel sub-agents in a single session, verify outputs, then report back. Available on Enterprise, Team, and Max plans. Useful for codebase-scale migrations and large refactors.
Should we switch from a different AI provider to Anthropic?
This release alone isn't a reason to switch. The practical gap between the top models from Anthropic, OpenAI, and Google is now measured in single-digit percentages on most benchmarks. Pick your AI provider based on security, compliance, integration, and ecosystem fit. Assume the model itself will be competitive whichever you choose.
When will Claude Mythos be available?
Anthropic say "in the coming weeks." Mythos currently only ships to Project Glasswing cybersecurity partners. General availability is gated on additional safeguards that Anthropic say are progressing quickly.
Sources
- Anthropic - Claude Opus 4.8 announcement
- Anthropic - Claude Opus 4.8 System Card
- Claude - Introducing Dynamic Workflows in Claude Code
- Anthropic - Project Glasswing initial update

Founder & CEO of Aztech IT Solutions, a UK-based MSP established in 2006. With 19 years of experience in managed IT services, cybersecurity, and digital transformation, Sean helps organisations leverage technology for competitive advantage.
Connect on LinkedIn